
La crawlabilité désigne la capacité d'un site web à être exploré par les robots des moteurs de recherche. Avant d'être positionné, un contenu doit être découvert, parcouru et compris par Googlebot. Sans crawlabilité, aucune indexation n'est possible, et donc aucune visibilité organique.
Qu'est-ce que la crawlabilité en SEO ?
Définition : que signifie "crawler" un site web ?
Crawler un site web, c'est le parcourir automatiquement de lien en lien pour en découvrir et en lire le contenu. Les moteurs de recherche envoient pour cela des programmes appelés robots d'exploration, crawlers. Googlebot est le plus connu d'entre eux.
Ces robots ne naviguent pas comme un humain : ils suivent les liens hypertextes de manière systématique, effectuent un fetch du code HTML de chaque page qu'ils atteignent, en extraient le contenu et les liens sortants, puis passent à la page suivante. Ce processus se répète en continu sur l'ensemble du web.
La crawlabilité c'est la facilité avec laquelle ce processus peut s'effectuer sur votre site. Un site bien crawlable permet au robot d'accéder à un maximum de pages utiles en un minimum de temps et de ressources.
Crawlabilité vs indexabilité : quelle différence ?
Il s'agit de 2 étapes différentes du traitement d'une page par Google.
- La crawlabilité concerne l'accès. Le robot peut-il atteindre la page et en lire le contenu, c'est-à-dire l'explorer jusqu'à la crawl depth où elle se situe ?
- L'indexabilité concerne le traitement. Une fois lue, la page peut-elle être ajoutée à l'index de Google pour apparaître dans les résultats de recherche ?
Une page peut être crawlable sans être indexable. C'est le cas d'une page accessible aux robots mais protégée par une balise noindex. Googlebot la visite, en lit le contenu, puis repart sans l'enregistrer dans son index. À l'inverse, une page non crawlable ne peut jamais être indexée, quelle que soit sa qualité. La crawlabilité est le prérequis de la visibilité organique.
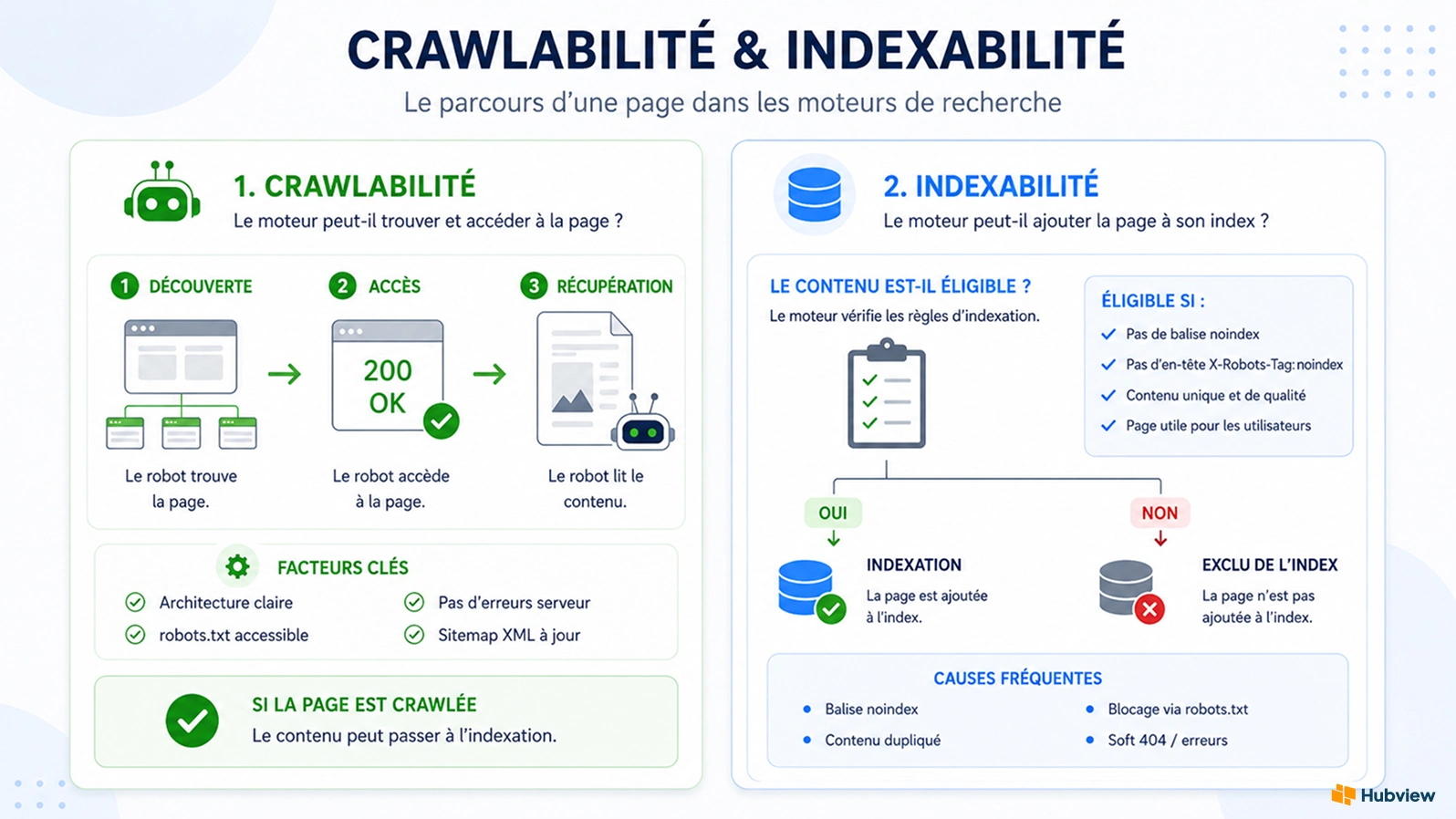
Comment fonctionne un robot d'exploration (Googlebot) ?
Le parcours de Googlebot suit 3 phases.
La découverte d'abord : le robot identifie les URLs à visiter à partir de deux sources principales. Les liens hypertextes présents sur des pages déjà connues, qu'il suit de proche en proche. Les sitemaps XML lui signalent les pages à explorer.
La visite ensuite : Googlebot envoie une requête HTTP à votre serveur, télécharge le code HTML de la page, puis charge les ressources (fichiers CSS et Javascript) pour rendre la page telle qu'un navigateur la verrait.
L'extraction enfin : le robot analyse le contenu textuel, les balises, les attributs des liens et les métadonnées. Il extrait les nouvelles URL présentes sur la page pour alimenter sa prochaine session d'exploration (sa crawl queue). Ces données sont transmises aux systèmes d'indexation de Google.
Importance de la crawlabilité pour votre référencement naturel
Une page non crawlée est une page non indexée
Le cycle du référencement naturel suit l'ordre crawl, indexation, classement. Une page absente de la première étape ne peut jamais atteindre les suivantes. Peu importe la qualité de son contenu, la pertinence de ses mots-clés ou le nombre de backlinks qui pointent vers elle. Si Googlebot ne l'a pas visitée, elle n'existe pas aux yeux de Google.
Budget de crawl : comment Google alloue ses ressources sur votre site ?
Google n'explore pas votre site de manière illimitée. Il attribue à chaque domaine un crawl budget c'est-à-dire un quota de pages qu'il accepte d'explorer sur une période donnée. Ce budget dépend de deux facteurs :
- Le crawl rate limit qui représente la fréquence maximale à laquelle Googlebot peut solliciter votre serveur sans le surcharger.
- La crawl demand qui reflète l'intérêt de Google pour vos pages selon leur popularité et leur fraîcheur.
Un site à forte autorité mis à jour fréquemment et techniquement propre, bénéficie d'un crawl budget élevé. Un site lent avec des erreurs ou publiant peu de contenu aura un budget réduit.
Quels facteurs nuisent à la crawlabilité de votre site ?
Une architecture de site mal structurée
La profondeur d'un site est mesurée en nombre de clics nécessaires pour atteindre une page depuis l'accueil. C'est l'un des premiers obstacles au crawl. Une page placée à 6 ou 7 niveaux de profondeur a peu de chances d'être découverte (surtout sur un domaine dont le crawl budget est limité). Googlebot privilégie les pages proches de la racine. Il les considère comme plus importantes dans la hiérarchie du site.
Les pages orphelines aggravent ce problème. Sans aucun lien interne entrant ces pages sont invisibles pour le robot même si elles figurent dans le sitemap XML. Le crawler suit les liens. Une page que rien ne relie au reste du site ne sera jamais atteinte par ce chemin et son existence dans le sitemap ne suffit pas à garantir sa découverte régulière.
Une arborescence trop large avec des centaines de catégories de même niveau sans hiérarchie produit le même effet. Le robot disperse ses ressources sans jamais approfondir l'exploration des sections les plus stratégiques.
Un fichier robots.txt trop restrictif
Le fichier robots.txt contrôle les autorisations d'accès des crawlers à votre site. Une directive Disallow mal configurée peut bloquer des sections entières que vous souhaitiez voir explorées. L'erreur la plus fréquente consiste à interdire l'accès aux ressources CSS et Javascript. Googlebot ne peut alors plus effectuer le render des pages ce qui compromet sa capacité à en évaluer le contenu.
Les chaînes et boucles de redirections
Chaque redirection consomme une fraction du crawl budget et allonge le chemin que Googlebot doit parcourir avant d'atteindre le contenu final. Une chaîne de redirections (l'URL A redirige vers B, qui redirige vers C, qui redirige vers D…) multiplie les requêtes HTTP sans apporter de valeur. Au-delà de trois ou quatre sauts, le robot peut abandonner la chaîne sans jamais atteindre la destination.
Une boucle de redirections arrive quand deux URLs se renvoient mutuellement l'une vers l'autre. Elles bloquent complètement l'exploration et génèrent des erreurs dans les fichiers de logs serveur.
Les erreurs 4xx et 5xx
Les erreurs 4xx signalent à Googlebot que la page demandée est inaccessible. Une erreur 404 sur une URL encore référencée dans le maillage interne ou dans des backlinks externes force le robot à consommer du crawl budget sur un contenu inexistant. Multipliées à l'échelle d'un site ces erreurs dégradent l'efficacité globale de l'exploration.
Les erreurs 5xx indiquent un problème côté serveur. Lorsque Googlebot rencontre des erreurs 503 ou 500 de manière répétée, il interprète le site comme instable et réduit progressivement son crawl rate pour ne pas aggraver la situation. Ce mécanisme de protection entraîne une baisse durable de la fréquence d'exploration dont les effets sur l'indexation peuvent persister plusieurs semaines après la résolution du problème technique.
Un temps de chargement trop élevé
Le time to first byte est le premier signal que reçoit Googlebot lors d'une visite. Un serveur qui met plus d'une seconde à répondre ralentit mécaniquement le nombre de pages que le robot peut explorer pendant le temps qu'il consacre à votre domaine. Sur un site de plusieurs milliers de pages, l'impact sur le crawl budget consommé est significatif. Les causes sont multiples : hébergement sous-dimensionné, une base de données non optimisée ou des temps de génération de pages trop longs.
Le contenu dupliqué et les URLs parasites
La duplication de contenu dilue le crawl budget sur des pages qui n'apportent aucune valeur supplémentaire. Les causes sont multiples : versions HTTP et HTTPS d'une même page coexistant sans redirection, URLs avec et sans slash final traitées comme des pages distinctes, paramètres de session ou de tracking générant des milliers de variantes d'une même URL.
Les filtres des sites e-commerce sont concernés. Une combinaison de filtres couleur, de taille et de prix peut produire des milliers d'URL. Sans gestion des URL canoniques, Googlebot dépense sont énergie à explorer ces variantes sans interêt.
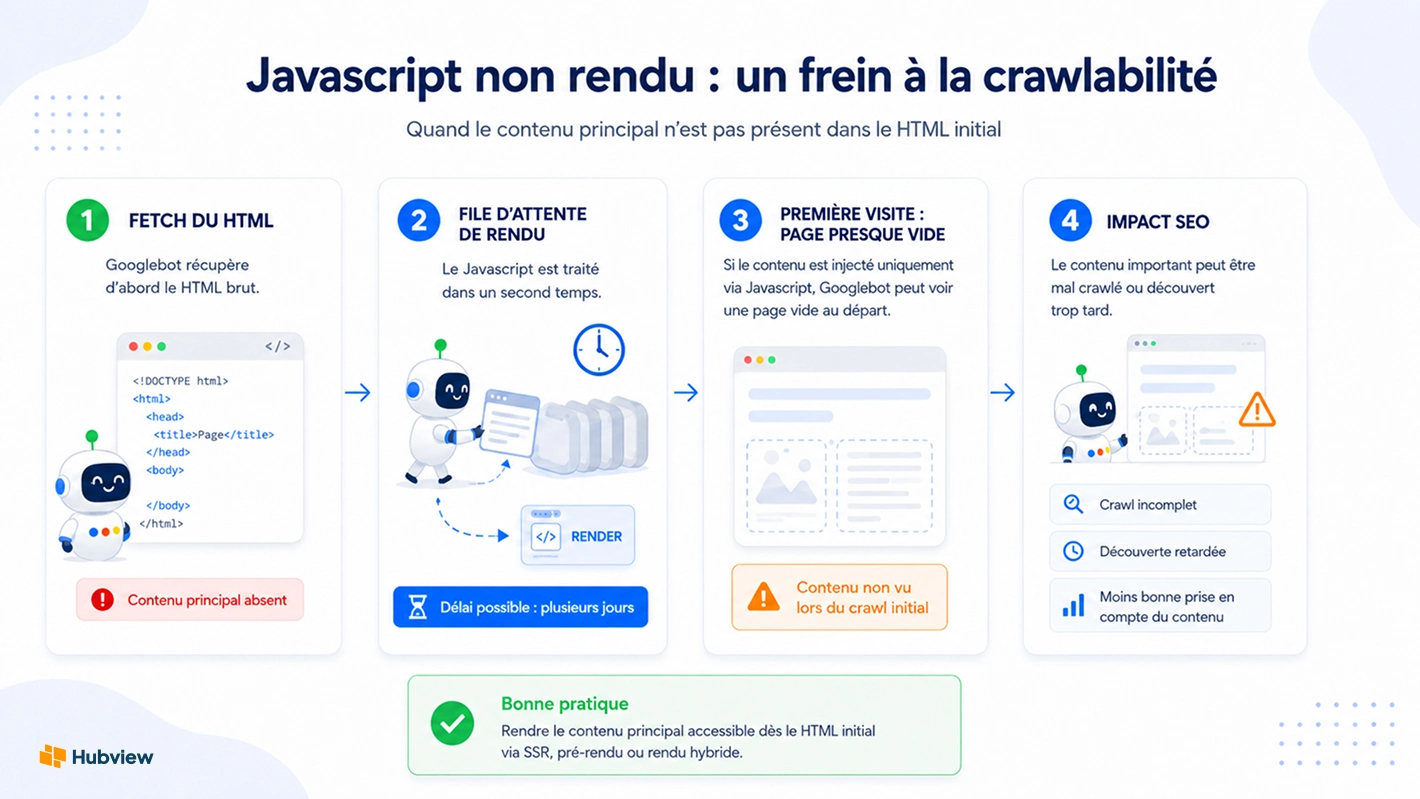
Le Javascript non rendu ou mal pris en charge
Googlebot traite le Javascript en deux temps. Il effectue d'abord le fetch du HTML brut, puis place la page dans une file d'attente de rendu pour exécuter les scripts dans un second temps. Ce délai entre le fetch initial et le render complet peut atteindre plusieurs jours sur les sites peu prioritaires.
Si votre contenu principal est injecté dans le DOM uniquement via Javascript et absent du HTML initial, Googlebot risque de crawler une page vide lors de sa première visite. Les frameworks Javascript côté client comme React, Vue ou Angular sont concernés lorsqu'ils ne sont pas associés à un rendu côté serveur ou à une solution de server-side rendering (SSR).
Comment améliorer la crawlabilité de votre site web ? Les 10 bonnes pratiques
1. Optimisez l'architecture et la profondeur de votre site
Aucune page stratégique ne devrait se trouver à +3 clics de la page d'accueil. Plus une page est proche de la racine, plus elle sera visitée et considérée comme prioritaire dans la hiérarchie du site.
Organisez vos contenus en silos thématiques / cocon sémantiques. Limitez le nombre de niveaux de profondeur à trois ou quatre maximum entre l'accueil et n'importe quelle page finale.
2. Renforcez votre maillage interne
Chaque page de votre site doit recevoir au moins un lien interne entrant depuis une autre page. C'est la condition minimale pour qu'elle soit découverte par le crawler lors d'une session d'exploration normale. Au-delà de cette règle de base, la qualité du maillage interne détermine la distribution du link equity à travers votre site et signale à Googlebot quelles pages méritent une attention prioritaire.
Multipliez les chemins vers vos pages stratégiques pour que le robot puisse les atteindre de plusieurs façons :
- Un lien depuis la navigation principale
- Un depuis des articles de blog
- un depuis des pages de catégorie parentes.
Placez vos liens contextuels en début de contenu éditorial plutôt qu'en fin de page ou dans le footer. Leur position influence leur poids dans le calcul du crawl priority.
3. Soumettez un sitemap XML à jour
Soumettez votre sitemap via Google Search Console et vérifiez régulièrement que le nombre d'URLs soumises correspond au nombre d'URL découvertes.
4. Configurez votre fichier robots.txt
Ciblez et bloquez les sections sans valeur SEO comme les espaces clients, paniers d'achat, pages de résultats de recherche interne, URL de filtres. Tout le reste doit rester accessible aux crawlers.
5. Gérez les redirections et éliminez les liens brisés
Chaque redirection dans votre maillage interne doit pointer vers la page finale. Auditez vos redirections avec un outil de crawl pour identifier les chaînes existantes et faites pointer chaque lien source directement vers l'URL canonique de destination.
Identifiez les erreurs 404 de la même façon. Un lien interne qui pointe vers une URL inexistante force Googlebot à consommer une requête HTTP pour obtenir un status code d'échec.
6. Vérifier la présence de balises canoniques
La balise canonique rel="canonical" indique à Googlebot quelle est la version de référence d'une page lorsque plusieurs URLs donnent accès à un contenu similaire. Elle évite que le robot ne disperse ses ressources sur des variantes d'URL sans valeur ajoutée.
Vérifiez qu'il y a bien des canoniques sur toutes vos pages paginées, les URLs avec paramètres de tracking. Chaque page doit se déclarer elle-même comme canonique.
7. Améliorez les performances liées au Core Web Vitals
Selon Google, Un time to first byte inférieur à 800 millisecondes est l'objectif à viser. À ce niveau de réactivité, Googlebot peut enchaîner les requêtes sans ralentissement ce qui maximise le nombre de pages explorées par unité de temps consacrée à votre domaine.
Investissez dans un hébergement dimensionné pour absorber les pics de crawl sans dégradation des temps de réponse. Activez la mise en cache serveur, compressez vos ressources statiques et réduisez le poids des pages pour accélérer leur chargement.
8. Publiez du contenu de qualité
La fréquence de crawl d'un site est corrélée à son rythme de publication. Googlebot ajuste sa crawl demand en fonction de la fraîcheur perçue de vos contenus. Un site qui publie plusieurs fois par semaine sera revisité plus souvent qu'un site qui ne change jamais.
Maintenez un calendrier éditorial et mettez à jour vos contenus les plus anciens dès qu'ils nécessitent une révision. Chaque publication ou mise à jour significative est un signal envoyé à Googlebot que votre site mérite une visite.
9. Demandez l'indexation de vos pages
L'outil d'inspection d'URL de Google Search Console permet de demander l'indexation d'une page auprès de Google. Après avoir saisi l'URL, le bouton "Demander l'indexation" déclenche une vérification par Googlebot qui visite la page en priorité sans attendre son prochain cycle d'exploration planifié.
10. Analysez vos fichiers de logs serveur
Les fichiers de logs sont la source de données la plus fiable pour comprendre le comportement réel de Googlebot sur votre site. Contrairement aux outils de crawl simulation qui reproduisent le comportement supposé du robot, les logs enregistrent chaque requête HTTP effectivement émise par Googlebot : l'URL visitée, la date et l'heure, le status code retourné, et le user-agent utilisé. Cette analyse révèle les pages que Googlebot ne visite jamais ou trop rarement.

Quels outils utiliser pour analyser et surveiller la crawlabilité ?
| Outil | Type | Points forts | Idéal pour |
|---|---|---|---|
| Google Search Console | En ligne, gratuit | Données officielles Google, rapport d'exploration, inspection d'URL | Diagnostic quotidien, suivi de couverture d'index |
| Screaming Frog | Bureau, freemium | Crawl simulé complet, comparaison entre audits, connexion GSC/GA | Audit technique trimestriel, détection de régressions |
| Semrush Site Audit | En ligne, payant | Audit automatisé récurrent, 140+ critères, alertes sur régressions | Suivi continu, priorisation des corrections |
| Log File Analyzer | Bureau/En ligne, payant | Comportement réel de Googlebot, croisement logs/GSC | Diagnostic avancé, analyse des patterns de crawl |
Comment mesurer et suivre la crawlabilité dans le temps ?
La crawlabilité se pilote dans le temps à partir d'indicateurs mesurables. Voici les KPI à suivre en priorité.
- Taux de crawl : nombre de pages explorées par Googlebot par jour. Une baisse soudaine sans modification technique de votre côté est un signal d'alerte à investiguer dans les logs serveur et la Search Console.
- Ratio pages crawlées / pages indexées : révèle l'efficacité de votre crawl budget. Un écart important entre les deux chiffres indique que Googlebot explore des URLs qui ne méritent pas d'être indexées, ou que des pages stratégiques sont crawlées sans jamais être retenues dans l'index.
- Taux d'erreurs par session de crawl : agrège les status codes 4xx et 5xx retournés à Googlebot. Un taux supérieur à 5% sur une période donnée nécessite une intervention technique. Ce chiffre est disponible dans le rapport Statistiques d'exploration de la Search Console.
- Temps de téléchargement moyen : réactivité de votre serveur telle que Googlebot la perçoit.
- Crawl depth moyen : profondeur moyenne à laquelle Googlebot atteint vos pages. Une valeur élevée signale une architecture trop profonde ou un maillage interne insuffisant sur les sections concernées.
FAQ
La crawlabilité est-elle un facteur de classement Google ?
Non au sens strict. Google ne classe pas un site mieux parce qu'il est bien crawlable. En revanche, sans crawlabilité, aucun classement n'est possible. Une page non crawlée ne peut pas être indexée, et une page non indexée n'apparaît dans aucun résultat. La crawlabilité est un prérequis au classement.
Combien de temps faut-il pour qu'une page soit crawlée après sa publication ?
Cela dépend de l'autorité du domaine, de la fréquence de crawl habituelle et de la position de la page dans l'arborescence. Sur un site à forte autorité avec suffisamment de maillage interne Googlebot peut découvrir une nouvelle page en quelques heures. Sur un site à faible crawl budget avec une architecture profonde, le délai peut dépasser plusieurs semaines.
Peut-on avoir un bon SEO avec une mauvaise crawlabilité ?
Non. Un contenu de qualité, des backlinks et une optimisation sémantique ne compensent pas une crawlabilité "défaillante". Si Googlebot ne peut pas accéder à vos pages, les lire correctement et les explorer régulièrement, aucun autre levier SEO ne produira d'effet. La crawlabilité est la fondation technique sur laquelle repose l'ensemble de la performance organique d'un site.
Quelle est la différence entre crawl budget et crawl rate ?
Le crawl rate est la fréquence maximale à laquelle Googlebot peut solliciter votre serveur sans le surcharger. Le crawl budget est le nombre total de pages que Google choisit d'explorer sur votre site sur une période donnée. Les deux sont liés : un serveur lent réduit le crawl rate, ce qui comprime le crawl budget disponible.
Comment savoir si Googlebot est bloqué sur mon site ?
Trois sources à consulter en priorité. 1/ Le rapport Statistiques d'exploration de Google Search Console, qui signale les erreurs rencontrées par Googlebot. 2/ Le fichier robots.txt, à tester avec l'outil dédié de la Search Console pour vérifier qu'aucune section stratégique n'est bloquée par inadvertance. 3/ Les fichiers de logs serveur, qui enregistrent chaque requête de Googlebot avec son status code retourné.