Qu'est-ce que les données structurées ? Définition
Les données structurées sont un format de balisage ajouté au code HTML des pages web pour indiquer aux moteurs de recherche la nature de leur contenu. Il s'agit d'un ensemble de balises standardisées qui permettent à Google, Bing ou Yandex de lire, interpréter et exploiter le contenu.
Cette page parle-t-elle d'un article de blog, d'une fiche produit, d'une offre d'emploi, d'un film ? Qui en est l'auteur ? Quel est le prix affiché ? Quelle note ont attribué les utilisateurs ? Ces informations sont invisibles pour le lecteur. Elles sont lues et utilisées par les moteurs de recherche pour enrichir l'affichage des pages dans les résultats.
Comment les moteurs de recherche lisent et interprètent vos données
Lorsqu'un robot d'indexation visite une page web, il analyse le contenu textuel et tente d'en déduire le sens. Sans données structurées cette interprétation est plus complexe. Ce crawler observe la densité de certains mots, la structure des titres, les liens internes. Le moteur fait des hypothèses, parfois inexactes.
Avec des données structurées vous supprimez cette ambiguïté. Le crawler lit les balises et sait qu'il se trouve face à une recette avec un temps de cuisson de 30 minutes, notée 4,7/5 par 240 utilisateurs (par exemple). Cette “certitude” lui permet d'activer des fonctionnalités d'affichage enrichi que le contenu textuel seul ne permettrait pas.
Ce processus s'appuie sur Schema.org, un vocabulaire partagé entre les grands moteurs de recherche dont nous détaillons le fonctionnement plus loin.
Données structurées, données non structurées et données semi-structurées : quelles différences ?
Les données non structurées représentent la majorité du contenu web. Il s'agit de textes, d'images, vidéos, audio. Ces données ne suivent aucun format prédéfini et leur interprétation par les machines nécessite des modèles d'analyse comme le NLP (Natural Language Processing). Par exemple un article de blog sans balisage est une donnée non structurée.
Les données semi-structurées suivent une organisation partielle sans respecter un schéma “strict”. Cela peut être un fichier CSV, un flux RSS, un sitemap XML ou un document HTML. Ils ont une structure qui facilite le traitement automatique mais n'offrent pas la même précision sémantique que des données structurées.
Les données structurées obéissent à un schéma précis. Chaque information est associée à une propriété définie dans un format standardisé. Les moteurs de recherche peuvent les utiliser pour afficher des rich snippets, alimenter le Knowledge Graph ou intégrer les contenus dans des Google Actualités. En SEO technique, on parle aussi de balisage sémantique pour définir cette pratique d'optimisation de la crawlabilité et de l'indexabilité de vos pages.
Les bénéfices des données structurées pour votre SEO
Rich snippets et résultats enrichis, une visibilité accrue dans les SERP
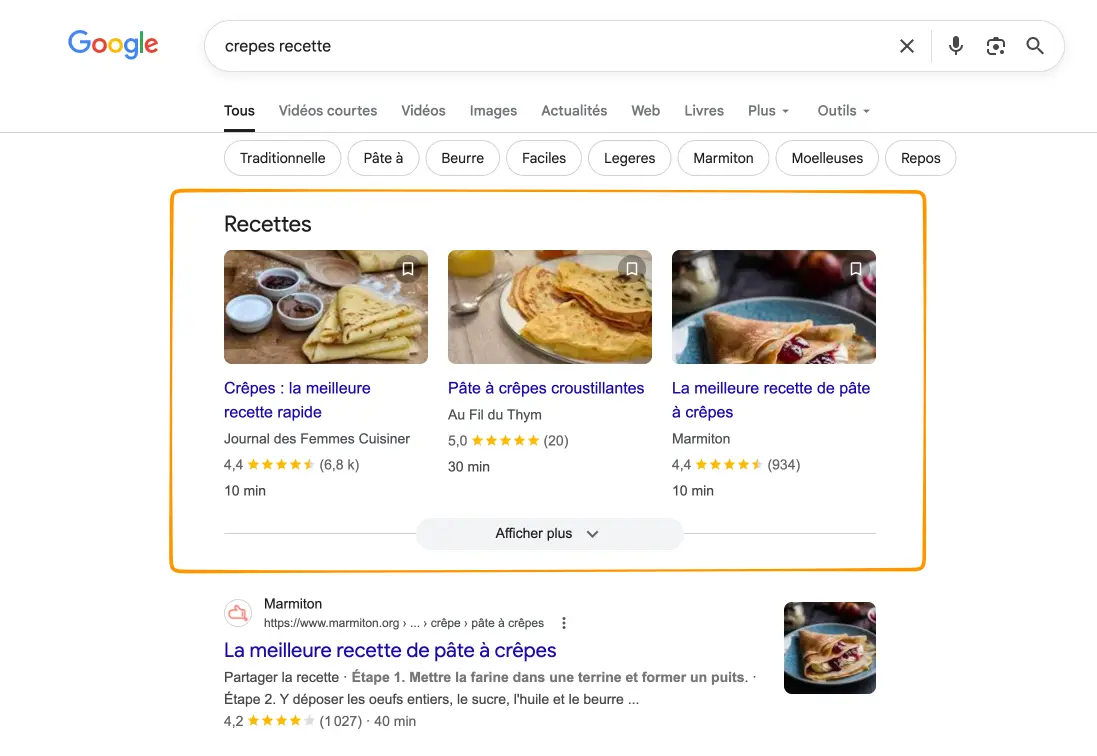
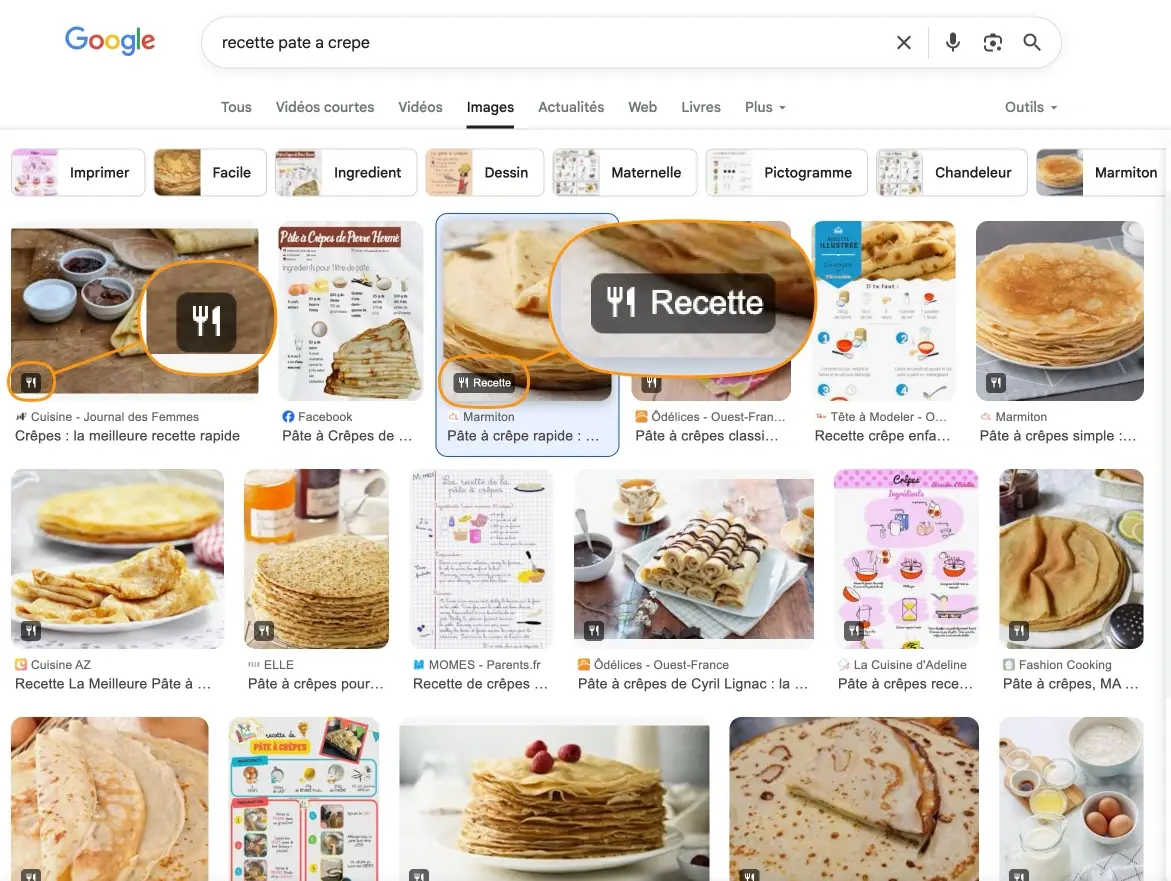
Un résultat de recherche standard affiche un titre, une URL et une meta-description. Un résultat enrichi (ou rich snippet) intègre des étoiles de notation, une image, un prix, une disponibilité produit, un temps de préparation ou des questions dépliables dans la SERP. Ces éléments visuels captent l'attention des internautes.
Ces rich snippets sont déclenchés par les données structurées. Sans balisage, Google peut techniquement extraire certaines informations de votre contenu via ses algorithmes de compréhension sémantique, mais cette extraction reste aléatoire et non garantie. Avec un balisage correct vous signalez les informations que vous souhaitez voir apparaître dans les résultats de recherche en tant que SERP features.
Les SERP features correspondent à l'ensemble des formats d'affichage proposés par Google. Featured snippets, knowledge panels, carrousels, image packs, local packs.
Amélioration du taux de clics sans impact direct sur le classement
Les données structurées n'influencent pas le positionnement dans l'index de Google. Elles n'agissent pas sur les signaux de ranking classiques comme le Pagerank, les backlinks ou les Core Web Vitals. En revanche leur effet sur le CTR est significatif.
Google Search Central recense lui-même plusieurs cas réels. Rotten Tomatoes a enregistré 25 % de CTR supplémentaire sur ses pages balisées, Nestlé a observé un CTR 82 % plus élevé sur ses pages apparaissant en rich results, et The Food Network a constaté 35 % de visites en plus après avoir converti 80 % de ses pages aux données structurées. Ces chiffres s'expliquent par la surface visuelle occupée dans la SERP et par la valeur informative que perçoit l'internaute (un prix affiché, une note, un temps de lecture). L'utilisateur dispose d'éléments de décision avant même de cliquer.
Vocabulaire et formats des données structurées
Schema.org, la référence pour structurer vos données
Schema.org est un balisage sémantique utilisé par les moteurs de recherche pour interpréter les données structurées. Il a été créé en 2011 à l'initiative conjointe de Google / Bing / Yahoo et Yandex. L'objectif était d'avoir un langage commun à tous les moteurs, quelle que soit la langue ou la localisation du site.
Schema.org définit des types c'est-à-dire des catégories de contenus comme Article, Product, Recipe, Event, Person ou LocalBusiness, ainsi des propriétés associées à chaque type. Par exemple, le type Recipe dispose de propriétés comme cookTime, recipeIngredient ou nutrition. Le type Product dispose de propriétés comme price, availability ou brand. Cette hiérarchie de types et de propriétés forme un système de représentation que les moteurs de recherche utilisent pour comprendre le web.
Schema.org c'est +800 types distincts sur des domaines variés comme la médecine, la finance, le sport ou l'éducation. En SEO, on utilise une vingtaine de types pour l'essentiel des cas d'usage.
JSON-LD, le format recommandé par Google et pourquoi le privilégier
JSON-LD (Javascript Object Notation for Linked Data) est le format d'implémentation des données structurées recommandé par Google. Il se présente sous la forme d'un bloc de code JS inséré dans la balise <head> ou <body> du contenu HTML visible.
La maintenance est simplifiée et sécurisée. Le code est dissocié du design donc vous pouvez ajouter, modifier ou supprimer des balises sans risquer de casser la mise en page.
Microdata et RDFa, cas d'usage et différences avec JSON-LD
Avant que le JSON-LD ne devienne la norme, le Microdata et le RDFa étaient les deux formats historiques pour baliser un site. Contrairement au JSON-LD (qui s'isole dans un bloc de script), ils partagent un même principe. Les données s'imbriquent au cœur du code HTML, au milieu des textes et des balises.
Les principaux types de données structurées reconnus par Google
Article et BlogPosting pour les contenus éditoriaux
Le type Article est le balisage dédié aux articles de blog, analyses, guides. Il permet à Google d'identifier la nature du contenu et de l'éligibilité à des fonctionnalités comme Google Actualités, les Top Stories ou l'affichage enrichi dans Google Discover. Les propriétés du type Article sont le titre (headline), l'image principale (image), l'auteur (author), la date de publication (datePublished) et la date de dernière modification (dateModified).
BlogPosting est un sous-type d'Article, dédié aux site éditoriaux ou un médias. Dans les deux cas, le balisage Author mérite une attention particulière : associé au type Person avec une URL de profil, il contribue directement aux signaux d'E-E-A-T en ancrant l'expertise de l'auteur dans le Knowledge Graph.
Product et Offer pour les pages e-commerce
Le type Product est le balisage central de toute stratégie SEO e-commerce. Il permet de décrire une fiche produit avec son nom, sa description, ses images, sa marque (brand), son identifiant unique (SKU ou GTIN) et ses caractéristiques techniques. Associé au type Offer, il permet d'exposer le prix, la devise, la disponibilité et les conditions de vente directement dans les résultats de recherche.
C'est cette combinaison Product et Offer qui déclenche l'affichage enrichi dans Google Shopping, permettant à vos fiches produits d'apparaître dans l'onglet Shopping sans nécessairement passer par Google Ads. C'est également ce balisage qui active l'affichage du prix et de la disponibilité dans les résultats organiques classiques, deux informations qui réduisent l'incertitude de l'acheteur avant le clic et améliorent la qualité du trafic entrant.
Le GTIN (Global Trade Item Number), qu'il s'agisse d'un EAN, d'un UPC ou d'un ISBN, est une propriété fortement recommandée pour les produits vendus par plusieurs marchands. Il permet à Google de faire correspondre votre fiche avec les données de son index de produits et d'enrichir davantage votre affichage. Les propriétés AggregateRating et Review, détaillées plus loin, viennent compléter ce balisage pour afficher les étoiles de notation.
Les données structurées pour l'e-commerce
Pour les boutiques en ligne, le balisage Product décrit vos produits avec leur nom, description, prix, disponibilité, avis clients et images. Associé au balisage Review, il permet d'afficher les précieuses étoiles de notation dans les résultats, un atout majeur pour se démarquer de la concurrence.
Le balisage Breadcrumb affiche le fil d'Ariane dans les résultats de recherche, remplaçant l'URL classique par un chemin cliquable. Cette navigation améliore l'expérience utilisateur et renforce la compréhension de votre arborescence par Google.
Les données structurées pour les contenus spécialisés
Le balisage FAQ et HowTo permet d'afficher des questions-réponses ou des étapes dépliables directement dans les SERP. Vous gagnez une visibilité énorme en occupant plusieurs lignes de résultats au lieu d'une seule. Attention toutefois, Google devient plus strict sur l'utilisation de ces balisages et peut les ignorer s'ils ne sont pas pertinents.
Le balisage Recipe transforme vos recettes en résultats ultra-attractifs avec photo, note, temps de préparation et calories. Les sites culinaires qui implémentent ce balisage augmentent leur trafic grâce aux carrousels de recettes.